We explore visual-geometry semantics in radiance fields, asking: Do geometry-grounded semantic features offer an edge in distilled fields? and introduce SPINE, a semantics-centric method for inverting radiance fields without an initial guess.
Semantic distillation in radiance fields has spurred significant advances in open-vocabulary robot policies, e.g., in manipulation and navigation, founded on pretrained semantics from large vision models. While prior work has demonstrated the effectiveness of visual-only semantic features (e.g., DINO and CLIP) in Gaussian Splatting and neural radiance fields, the potential benefit of geometry-grounding in distilled fields remains an open question. In principle, visual-geometry features seem very promising for spatial tasks such as pose estimation, prompting the question: Do geometry-grounded semantic features offer an edge in distilled fields? Specifically, we ask three critical questions: First, does spatial-grounding produce higher-fidelity geometry-aware semantic features? We find that image features from geometry-grounded backbones contain finer structural details compared to their counterparts. Secondly, does geometry-grounding improve semantic object localization? We observe no significant difference in this task. Thirdly, does geometry-grounding enable higher-accuracy radiance field inversion? Given the limitations of prior work and their lack of semantics integration, we propose a novel framework SPINE for inverting radiance fields without an initial guess, consisting of two core components: (i) coarse inversion using distilled semantics, and (ii) fine inversion using photometric-based optimization. Surprisingly, we find that the pose estimation accuracy decreases with geometry-grounded features. Our results suggest that visual-only features offer greater versatility for a broader range of downstream tasks, although geometry-grounded features contain more geometric detail. Notably, our findings underscore the necessity of future research on effective strategies for geometry-grounding that augment the versatility and performance of pretrained semantic features.
Increasingly, robot policies have embedded semantics from vision foundation models into radiance fields to enable language-conditioned robot manipulation, mapping, and object localization. However, these policies are generally limited to visual-only image features (e.g., DINO) combined with the vision-language semantics of CLIP. Here, we present an method for distilling visual-geometry semantics into radiance fields. We extract ground-truth pretrained semantic embeddings for each image from the depth and point heads of VGGT and its intermediate layers, which were trained for depth estimation and dense point cloud reconstruction, respectively. We visualize these semantic embeddings on the right side of the figure using the first three principal components. We learn a semantic field \({f_{s}: \mathbb{R}^{3} \mapsto \mathbb{R}^{d_{s}}}\), which maps a 3D point \(\mathbf{x}\) to visual-geometry features \(f_{s}(\mathbf{x})\) alongside a semantic field \({f_{l}: \mathbb{R}^{3} \mapsto \mathbb{R}^{d_{l}}}\) that maps 3D points to the shared image-language embedding space of CLIP. For effective co-supervision of both semantic fields, the VGGT and CLIP semantic fields share the same hashgrid encodings (i.e., base semantics), associating their semantic embeddings with the same visual and geometric features, illustrated in the left side of the figure.
We examine the performance of visual-geometry semantic features compared to visual-only features in distilled radiance fields. Via extensive experiments on three benchmark datasets (LERF, 3D OVS, and Robotics datasets), we explore the following questions, spanning the core applications of distilled radiance fields in robotics:
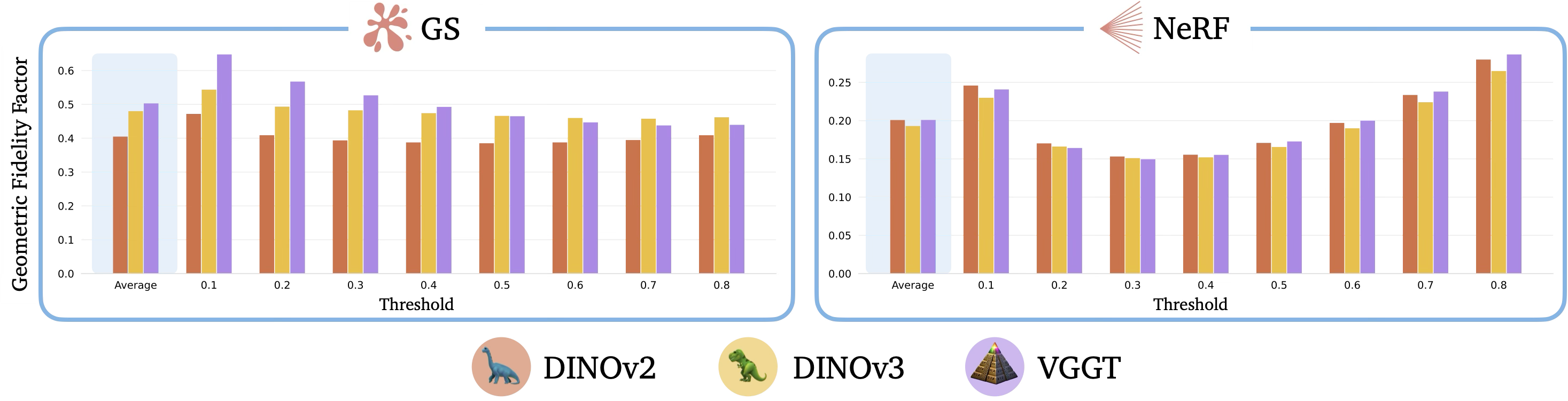
We use the geometric fidelity factor (GFF) to quantitatively assess the geometric content of distilled features, which captures the edge information present in the semantic features relative to the physical scene, as determined by the RGB image. We apply the Sobel-Feldman filter to the semantic images and extract the edges contained in these images at different resolutions, by varying the threshold of the edge gradient. We aggregate the quantitative results for all scenes and plot the GFF against gradient thresholds. For GS, we see that VGGT's features have the most edges at lower gradient thresholds, with DINOv2's features having the least, consistent with our qualitative observations. Moreover, we observe that the GFF of DINOv2 and DINOv3 remains almost constant across different thresholds, suggesting a lack of diversity in their geometric content, unlike VGGT. We visualize the results for the 3D OVS Bed, LERF Teatime, Robotics Quadruped Kitchen scenes with thresholds of 0.1 and 0.3. Even at the lowest threshold of 0.1, we observe more prominent geometry in the VGGT features in all scenes, except the 3D OVS scene. Increasing the gradient threshold leads to an overall decrease in the number of edges contained in the spatially-grounded and visual-only features. However, VGGT still provides the most structural content.
Furthermore, we project the distilled semantic features into a three-dimensional subspace using the first-three principal components to aid visualization. We show the PCA visualization of the semantic features in the same scenes, highlighting the object-level composition of the scene. For example, in the Teatime scene, we observe that the DINOv2 and DINOv3 features for the bear and the sheep are strongly distinct from the table and chairs, underscoring their focus on object-level decomposition. In contrast, VGGT features emphasize the geometric details of the scene, evidenced by the prominent edges of the bear, sheep, table, and chair, although some object-level features are visible.
RGB
DINOv2
DINOv3
VGGT
RGB
DINOv2
DINOv3
VGGT
RGB
DINOv2
DINOv3
VGGT
RGB
DINOv2
DINOv3
VGGT
RGB
DINOv2
DINOv3
VGGT
RGB
DINOv2
DINOv3
VGGT
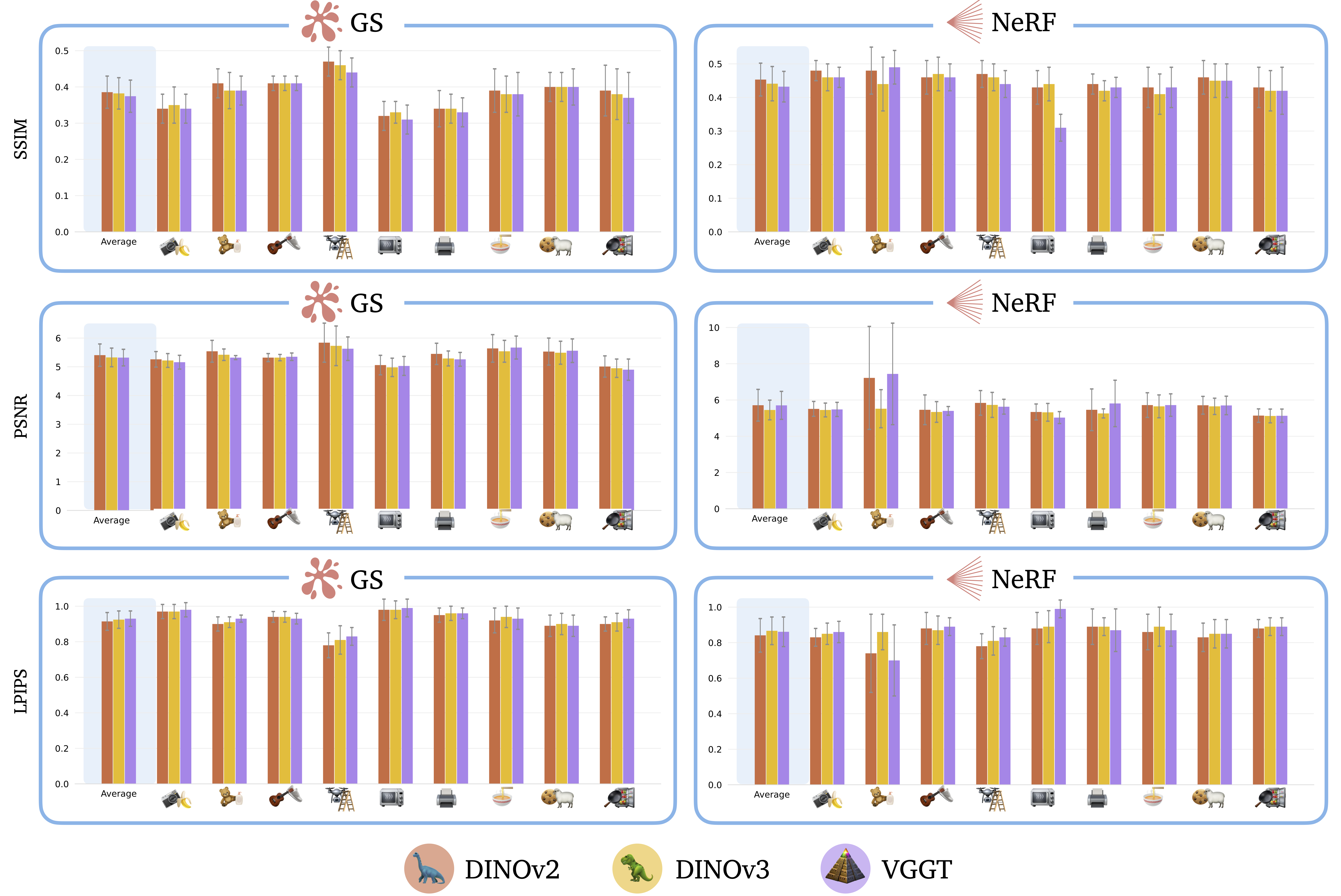
We examine the performance of spatially-grounded vs. visual-only features in semantic object localization. In each scene, we use CLIP to encode the natural-language queries and subsequently generate the continuous relevancy mask. We use GroundingDINO and SAM-2 to annotate the ground-truth segmentation mask, used in computing the segmentation accuracy metrics: SSIM, PSNR, and LPIPS. After aggregating the results across all scenes, we find no significant difference in the localization accuracy of visual-only vs. visual-geometry features across GS and NeRF, suggesting that both semantic features are effective in co-supervising CLIP for open-vocabulary localization. However, we observe marginal degradation in performance with geometry-grounded features (VGGT). In addition, we visualize the ground-truth RGB and segmentation mask and the relevancy masks in six scenes.
DINOv2
DINOv3
VGGT
DINOv2
DINOv3
VGGT
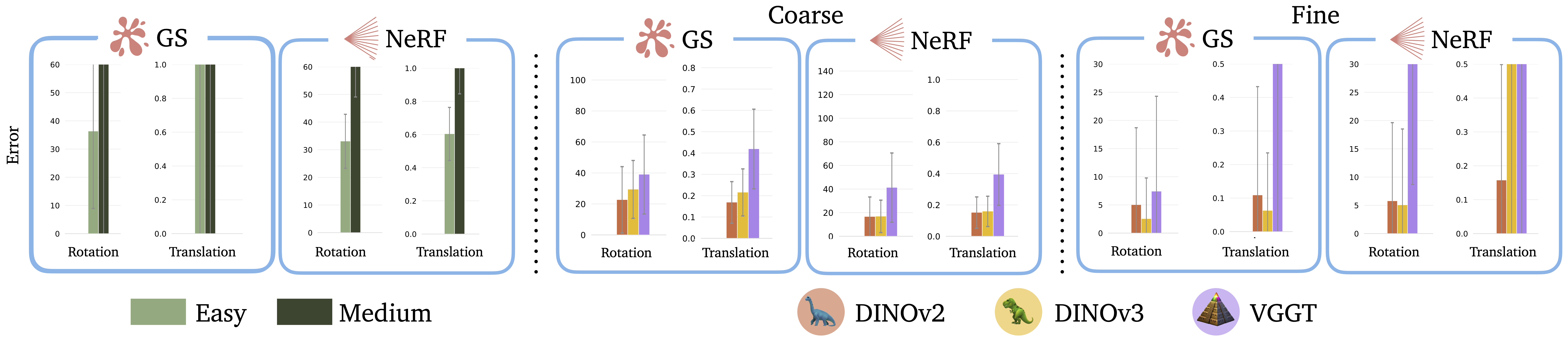
We evaluate the accuracy of visual-only and spatially-grounded features in radiance field inversion. Surprisingly, we find that visual-geometry features underperform visual-only features. Specifically, in the coarse pose estimation phase which significantly relies on semantics, DINOv2 achieves the lowest rotation and translation errors, while VGGT computes the least accurate pose estimates. These results suggest that DINOv2 features might be better suited for coarse pose estimation compared to VGGT features, despite the geometry-grounding procedure. Consequently, our findings indicate that existing methods for geometry-grounding may degrade the versatility of semantic features as general-purpose image features, constituting an interesting area for future work.
Further, we compare SPINE to existing baseline methods for radiance field inversion.
Particularly, we compare DINOv2-based SPINE with
Splat-Nav
and
iNeRF
for pose estimation in GS and NeRFs, respectively. Since the baselines require an initial guess, we
assess the performance of the baselines across two initialization domains, defined by the magnitude
of the initial rotation and translation error, \(R_{\mathrm{err}}\) and \(T_{\mathrm{err}}\),
respectively:
(ii) low initial error with \({R_{\mathrm{err}} = 30\deg}\), \({T_{\mathrm{err}} = 0.5\mathrm{m}}\),
and
(iii) medium initial error with \({R_{\mathrm{err}} = 100\deg}\), \({T_{\mathrm{err}} =
1\mathrm{m}}\).
We
reiterate that SPINE does not utilize any initial guess.
Our results highlight that the baselines struggle without a
good initial guess. Unlike these methods, SPINE computes more accurate pose estimates using
semantics in the coarse phase, without any initial guess. Moreover, via photometric optimization,
SPINE improves the accuracy of the coarse estimates. However, we note that the success of fine
inversion depends on the relative error magnitude of the coarse pose estimates. Particularly, DINOv2
generally achieves the highest success rate in the fine pose estimation phase, primarily due to its
higher-accuracy coarse pose estimates. Here, we show the unweighted mean and standard deviation
of the errors of the fine pose estimates.
@misc{mei2025geometrymeetsvisionrevisiting,
title={Geometry Meets Vision: Revisiting Pretrained Semantics in Distilled Fields},
author={Zhiting Mei and Ola Shorinwa and Anirudha Majumdar},
year={2025},
eprint={2510.03104},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.03104},
}
